
You’re building a search feature and the results are fixed to keywords. Users search for “project management tools” and should get articles about “task scheduling software” — which are related, but your system doesn’t know that. Or you’re trying to build a recommendation engine that suggests “similar” content, but similar according to who? Traditional databases can find exact matches, but they’re clueless about meaning and relationships.
This is the problem that vector databases solve, and they’re doing it behind the scenes in most AI applications you use daily. Netflix recommendations, Google search results, ChatGPT’s ability to find relevant information – they all rely on this technology to understand similarity and meaning rather than just matching keywords.
In this post we will cover what vector databases actually do, why modern applications need them, and how they work.
Turning everything into numbers that mean something
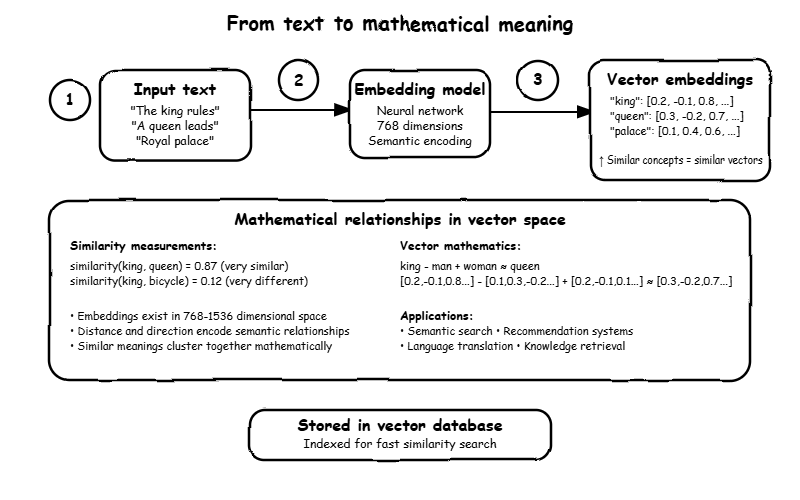
Here’s the core concept: vector databases store everything as lists of numbers called vectors. But these aren’t random numbers – they’re carefully created to capture the meaning of whatever you’re storing.
When you feed text like “The king rules the kingdom” into an AI model, it gets converted into something like [0.2, -0.1, 0.8, 0.3, -0.5, …] – typically a list of 700+ numbers. The clever part is that similar concepts get similar numbers.
So “king” and “queen” end up with very similar vectors, while “king” and “bicycle” get completely different ones. This isn’t magic – it’s the result of training AI models on massive amounts of text to understand relationships between words and concepts.
Why this matters
Once everything is stored as these meaningful number lists, you can ask questions like “find me documents similar to this one” and get genuinely useful results. The database compares the numbers mathematically to find the closest matches.
This is why AI chatbots can understand that “I need help with my account” and “Having trouble logging in” are related requests, even though they share no common words.
How vector databases actually work
The challenge is speed. When you have millions of these number lists, comparing your query against every single one would take forever. Vector databases solve this with clever indexing tricks.
The highway system approach (HNSW)
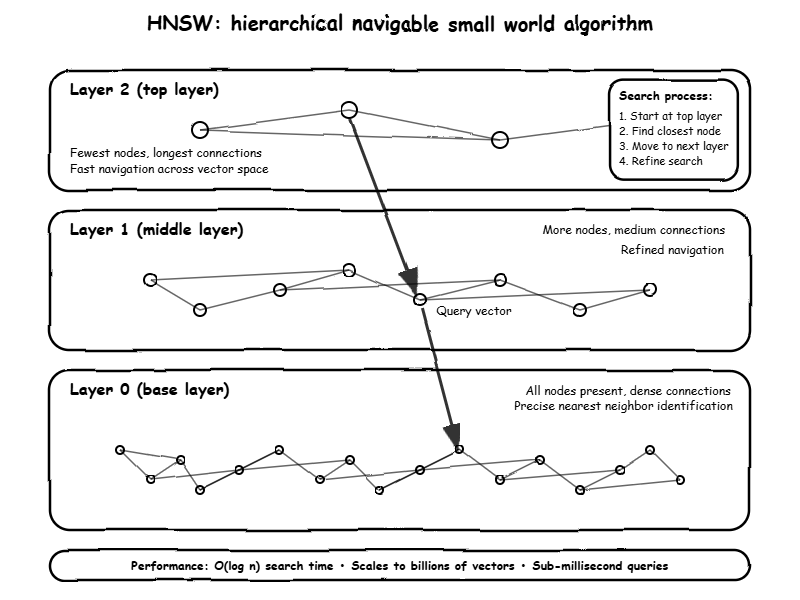
The most popular method is called HNSW – Hierarchical Navigable Small World algorithm. Don’t let the name intimidate you; the concept is actually quite elegant.
HNSW works exactly like a highway system for your data. Imagine you’re trying to get from London to a specific street in Edinburgh. You don’t drive through every single village along the way. Instead, you take major motorways to get close to Edinburgh quickly, then use local roads to find the exact address.
HNSW creates multiple layers of connections:
- Top layer (motorways): Has just a few major “highways” connecting distant concepts across the entire dataset
- Middle layers (A-roads): More connections, like regional roads that get you closer to your destination
- Bottom layer (local streets): Every piece of data is here, connected like local streets in a neighborhood
When you search, the algorithm starts at the top layer and takes big jumps through the data space to get close to what you want. Then it moves down layers, taking smaller and more precise steps until it finds the best matches. This lets you search through millions or even billions of items in milliseconds.
There’s another popular approach called IVF (Inverted File) that works more like organizing a massive library by subject. It groups similar items into clusters first, then only searches the most relevant sections. Both methods are effective, but HNSW tends to be faster for most real-world applications, so we’ll focus on that approach in this post.
The multi-layer approach lets you search billions of items in milliseconds
The clustering approach
Another common method groups similar items into clusters, like organizing a massive library by subject. When you search, the system first figures out which sections might have what you want, then only searches those areas. Much faster than checking every single book.
What vector databases actually power
Here’s where it gets practical. Vector databases are the hidden engine behind most AI features you use every day.
Smart search that understands what you mean
Traditional search matches keywords. Vector-powered search understands concepts. Search for “companies struggling with remote work” and it’ll find articles about “businesses facing telecommuting challenges” even though they don’t share any words.
Chatbots that don’t give dumb answers
As we covered in our previous post on corporate RAG training, vector databases help AI chatbots give accurate answers by finding the right information to reference. Instead of making stuff up, the AI can pull from your actual company documents.
Recommendations that don’t suck
Netflix, Spotify, Amazon – they all use vector databases to understand both what you like and what items are similar to those preferences. It’s why Netflix can recommend a Korean thriller when you’ve been watching British crime dramas.
Image search with words
Some vector databases can store both text and images as the same type of numbers. This means you can search for photos by typing “red car in the rain” or find products by uploading a picture. Same mathematical principles, different types of data.
How it all fits together
The diagram below shows the complete flow of how vector databases power AI applications. Let’s walk through each step:
Step 1 – Data sources: Everything starts with your raw data – documents, images, audio files, whatever you want to make searchable. This could be your company’s knowledge base, product catalog, or customer support tickets.
Step 2 – Embedding model: This is where the magic happens. The embedding model (usually a neural network) converts your data into those meaningful number lists we talked about. Documents about similar topics get similar numbers.
Step 3 – Vector database storage: The vectors get stored with smart indexes (like HNSW or IVF) that make searching fast. Plus any metadata like dates, categories, or tags that help filter results.
The query processing pipeline (the middle section) shows what happens when someone actually searches:
- User query: Someone types “Find similar documents” (or uploads an image, or asks a question)
- Query embedding: The same embedding model converts their query into a vector like [0.2, -0.1, …]
- Similarity search: The database compares this query vector against all stored vectors using math to find the closest matches
- Ranked results: Returns the most similar content, sorted by how close the match is, plus any relevant metadata
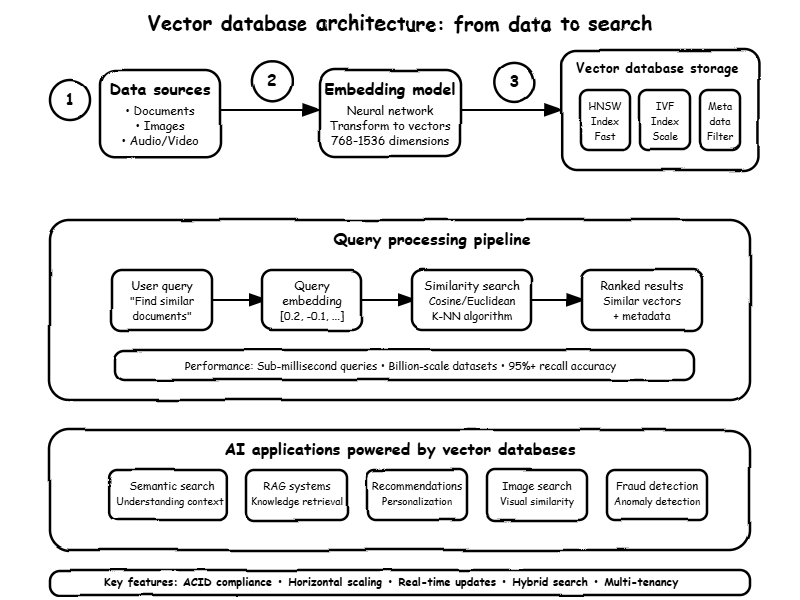
This whole pipeline typically happens in milliseconds, even when searching through millions of documents. The performance box shows why this matters: sub-millisecond queries across billion-scale datasets with 95%+ accuracy.
At the bottom, you can see all the AI applications this enables – from semantic search to fraud detection. Same underlying technology, different use cases.
The complete pipeline: data goes in, AI-powered features come out
The practical tradeoffs you need to know
Like any technology, vector databases involve tradeoffs. Understanding these helps you make better decisions.
Speed vs accuracy
Most vector searches are “good enough” rather than perfect. The system might find the 5th most similar item instead of the absolute best match, but it does it in microseconds instead of minutes. For most use cases, this is totally fine.
Memory vs storage costs
Those number lists take up space. A million documents might need several gigabytes of storage. The good news is that compression techniques can shrink this by 10–50x without losing much accuracy.
Setup time vs query speed
Building the indexes takes time upfront — sometimes hours for large datasets. But once built, searches are incredibly fast. It’s like spending time organizing your garage so you can find things instantly later.
Choosing the right option
You’ve got two main paths when adding vector capabilities to your applications.
Dedicated vector databases
Companies like Pinecone, Weaviate, and Qdrant built databases specifically for vectors. They handle all the complex math for you and often include features like automatic text-to-vector conversion and hybrid search that combines traditional filters with similarity search.
These are usually the best choice if you’re building AI features from scratch or need maximum performance.
Adding vectors to existing databases
PostgreSQL (with pgvector), Elasticsearch, and others now support vector storage alongside regular data. This works well if you already have infrastructure in place and want to add AI features gradually.
The performance might not be as good as specialized solutions, but the operational simplicity can be worth it.
Where this is all heading
Vector databases are evolving fast as AI gets more sophisticated:
Context-aware vectors
Right now, the word “bank” gets the same vector whether you’re talking about money or rivers. Future systems will create different vectors based on context, making AI even more accurate.
Smaller and faster
As AI moves to phones and edge devices, vector databases are getting more efficient. New compression techniques and specialized chips are making powerful search possible on limited hardware.
Better structure understanding
Instead of treating everything as isolated points, newer approaches can understand hierarchies and relationships. Think of it as the difference between a pile of photos and a well-organized photo album with categories and subcategories.
Vector databases might sound technical, but they’re solving a very human problem: helping computers understand similarity and meaning the way we do.
In conclusion
Whether you’re building search features, chatbots, recommendation systems, or any AI application that needs to understand relationships between data, vector databases are probably part of the solution.
The math behind them is complex, but using them doesn’t have to be. Most vector database providers offer simple APIs that handle the complicated parts for you. You focus on your application logic, they handle the similarity search.
As AI becomes more common in everyday applications, understanding vector databases gives you insight into how the “smart” parts actually work. And that understanding helps you build better AI features that users will actually find useful.
Learn more
- Pinecone’s Beginner Guide — Practical introduction with examples
- Vector Embeddings Explained — More detail on how the number conversion works
- Elasticsearch Vector Guide — Good overview of real-world applications
- Understanding RAG Architecture — How vector databases power smarter chatbots