
Apple’s latest research has delivered a stark challenge to the AI industry: 65% of leading AI models fail basic reasoning tests when presented with irrelevant information. This finding directly contradicts OpenAI’s claims that their o1 model represents genuine logical thinking, achieving 83% accuracy on advanced mathematics competitions. The disagreement between these AI giants has triggered the most significant debate in artificial intelligence history, with implications extending into healthcare, education, and automated decision-making systems that millions rely on daily.
Apple’s challenge: the fragility of machine reasoning
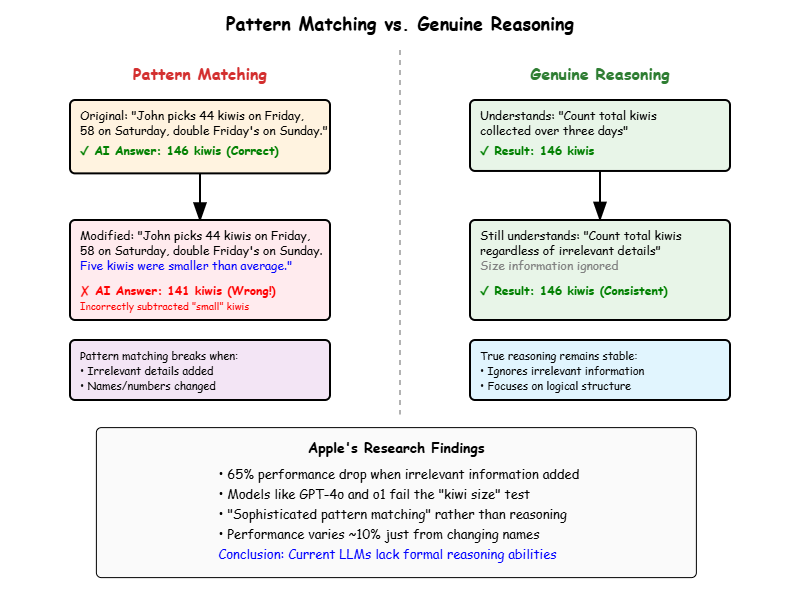
Apple’s research team developed GSM-Symbolic, a new benchmark that modifies the widely-used GSM8K mathematical reasoning dataset by changing names, numbers, and adding irrelevant information. The results were devastating across multiple leading models.
In the most revealing test, researchers added the irrelevant detail that “five of the kiwis were smaller than average” to a fruit-counting problem. Multiple AI models, including OpenAI’s advanced systems, incorrectly subtracted these kiwis from the final count despite size having no bearing on the total number.
“We found no evidence of formal reasoning in language models,” concluded the Apple research team led by Mehrdad Farajtabar. “Their behaviour is better explained by sophisticated pattern matching — so fragile, in fact, that changing names can alter results by approximately 10%”.
Performance drops ranged from 17.5% for OpenAI’s o1 Preview to 65% for Microsoft’s Phi 3 when irrelevant information was added. Even changing only numerical values caused significant variance, suggesting memorisation rather than genuine understanding across over 20 tested models.
OpenAI’s counter-argument: defending breakthrough claims
OpenAI maintains that their o1 model represents a genuine breakthrough through reinforcement learning that teaches models to “think before they answer” using extended chain-of-thought processing. Their evidence centres on benchmark performance rivalling human experts.
On the American Invitational Mathematics Examination (AIME), designed for America’s brightest high school students, o1 achieved 74% accuracy with single attempts and 93% with multiple tries — placing it amongst the top 500 students nationally. The model also demonstrated PhD-level performance on GPQA diamond, requiring expertise in chemistry, physics, and biology.
OpenAI argues that Apple’s identified fragility can be addressed through improved prompting techniques, highlighting a key philosophical divide: whether true reasoning should be robust to distracting information without extensive guidance. The company emphasises that o1’s performance improves with both training and inference time, suggesting scalable pathways towards genuine reasoning capabilities.
The scientific divide: pattern matching or genuine intelligence?
The reasoning controversy intersects with broader debates about “emergent abilities” in large language models. Stanford researchers published influential work titled “Are Emergent Abilities of Large Language Models a Mirage?” arguing that apparent sudden capability leaps result from poorly chosen evaluation metrics rather than genuine breakthroughs.
The scientific community remains sharply divided. IBM’s Ash Minhas supports Apple’s position: “This paper has fundamentally proven that LLMs can’t reason — they’re just pattern matching.” Meanwhile, AI researcher Gary Marcus views the findings as validation of decades-old concerns about neural network limitations.
However, other researchers argue that whilst LLMs may not demonstrate formal logical reasoning, they exhibit “probabilistic, memorisation-influenced noisy reasoning” that provides substantial practical value. Independent studies show LLMs struggle to defend their reasoning when challenged by invalid arguments, suggesting they may not grasp fundamental principles underlying their responses.
How leading AI researchers and institutions align on the spectrum of LLM reasoning capabilities
Real-world stakes: beyond academic arguments
The reasoning debate carries profound implications for AI deployment in critical applications. Research on human-AI collaboration warns that “variability, prompt brittleness, and inconsistencies in LLM outputs pose significant challenges for effective human interaction”.
Healthcare presents particularly high stakes, where studies reveal users increase trust in LLM responses when accompanied by explanations — even deceptive ones. Financial applications require algorithmic reliability for regulatory compliance, whilst educational systems must balance AI assistance with maintaining students’ critical thinking skills.
Many researchers advocate hybrid approaches combining LLM capabilities with traditional rule-based systems. As one researcher noted: “Maybe the future is a combination of different compute types — some intuitive pattern recognition from LLMs, coupled with hard logical rules from traditional programming”.
The evaluation challenge: measuring machine intelligence
At the debate’s heart lies a fundamental challenge: how to properly evaluate AI capabilities. Apple researchers highlight widespread data contamination, noting that “the GSM-8K dataset is such an industry benchmark that there are bits and pieces of it all over the training data that all models know about”.
Companies like Gretel AI have responded by developing synthetic datasets that “surpass the quality of both the OpenAI GSM8K and Apple GSM-Symbolic datasets” to differentiate between memorisation and genuine understanding.
Critics argue Apple’s studies lack human control groups, noting that changing word meanings and inserting distractions also increase human error rates. This raises questions about whether identified fragility is unique to artificial systems. AI researcher Melanie Mitchell highlights the definitional challenge: “Reasoning is one of those overburdened terms that includes abilities for deduction, induction, abduction, analogy, common sense, and other rational methods for solving problems”.
Looking ahead: the future of AI reasoning
The field rapidly evolves with new approaches to inference-time scaling, reinforcement learning, and hybrid architectures. Large Reasoning Models (LRMs) like OpenAI’s upcoming o3 and DeepSeek-R1 represent latest attempts to address traditional language model limitations.
As Mitchell observes: “If robust general-purpose reasoning abilities have emerged in LLMs, this bolsters the claim that such systems are an important step towards trustworthy general intelligence. On the other hand, if LLMs rely primarily on memorisation and pattern-matching rather than true reasoning, then they will not be generalisable”.
Apple researchers emphasise the broader stakes: “Understanding the true reasoning capabilities of LLMs is crucial for their use in real-world scenarios where accuracy and consistency are essential — specifically in AI safety, alignment, education, healthcare, and decision-making systems”.
The verdict: sophisticated mimicry or genuine intelligence?
Current evidence suggests large language models excel at sophisticated pattern matching and can solve complex problems through learned associations, but struggle with genuine logical reasoning when faced with novel variations or distracting information. This doesn’t diminish their practical value but informs how they should be integrated into critical systems.
As Gary Marcus concludes: “Nothing that I have read, verified, or done gives me any compelling reason to believe that LLMs do reasoning/planning, as normally understood. What they do instead, armed with web-scale training, is a form of universal approximate retrieval”. Yet this “approximate retrieval” has proven remarkably powerful for many applications.
For practitioners and policymakers, the key is maintaining healthy scepticism whilst recognising genuine capabilities — preparing for a future where AI reasoning may be powerful but fundamentally different from human cognition. The Apple-OpenAI debate will likely intensify as new models emerge, but the fundamental question remains: can pattern matching, no matter how sophisticated, ever truly constitute reasoning