
Enterprise data is often described as the “new oil” of business, but for most companies, that oil remains largely untapped. While organizations sit on vast repositories of documents, reports, manuals, and institutional knowledge, accessing and leveraging this information effectively has remained a persistent challenge. Enter Retrieval-Augmented Generation (RAG) – a breakthrough approach that’s finally allowing companies to transform their scattered corporate data into intelligent, responsive AI systems.
RAG represents a fundamental shift from training expensive custom language models to creating smart systems that can dynamically access and reason over your existing data. Recent industry data shows that 73% of enterprise RAG implementations are happening in large organizations, with companies choosing RAG for 30-60% of their AI use cases. The reason is simple: RAG delivers the power of custom AI without the astronomical costs and complexities of traditional model training.
Let’s explore how your company can harness this technology to unlock the collective intelligence buried in your corporate data.
What is RAG and why does it matter for enterprises?
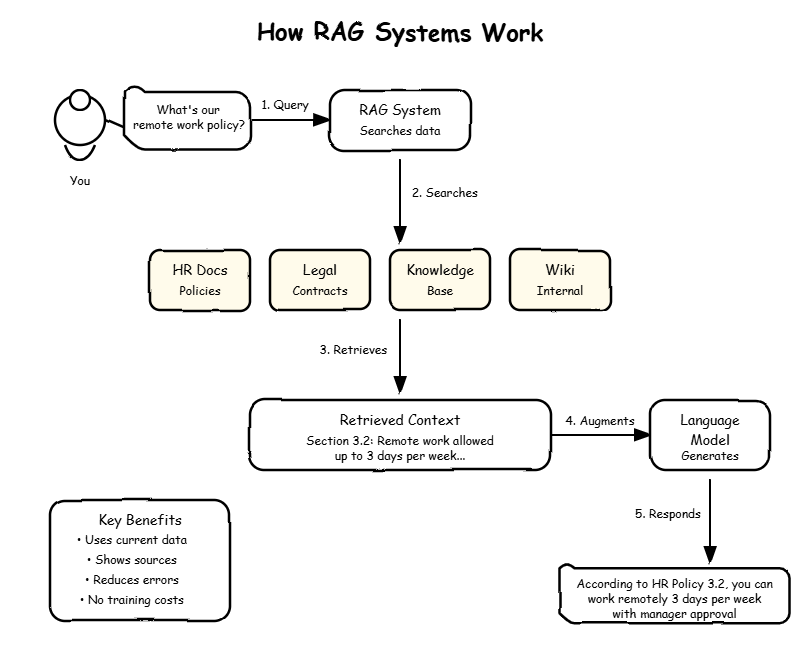
Retrieval-Augmented Generation might sound complex, but the concept is straightforward. Instead of training a language model from scratch on your corporate data (which would cost millions and take months), RAG connects existing language models to your company’s information in real-time.
Think of it this way: imagine you have a brilliant new employee who’s incredibly smart but knows nothing about your company. Traditional training would involve months of intensive onboarding. RAG is like giving that employee instant access to your company’s entire knowledge base, complete with a search system that can instantly find and reference the most relevant information for any question.
Here’s how RAG works in practice:
- Data preparation: Your corporate documents, databases, and knowledge repositories are processed and converted into searchable formats
- Query processing: When someone asks a question, the system searches your data to find the most relevant information
- Augmented generation: A language model uses both the question and the retrieved corporate data to generate accurate, contextual responses
- Source attribution: The system shows exactly where the information came from, enabling verification and trust
What makes this approach so powerful is that it combines the reasoning capabilities of advanced AI with the specific, up-to-date knowledge that exists only within your organization.
The enterprise data challenge
Before diving into RAG implementation, it’s crucial to understand the scope of the challenge that most enterprises face with their data. According to recent surveys, the top concerns companies have when trying to leverage their data for AI include:
- Data quality and consistency – Information scattered across systems with different formats and standards
- Scalability and performance – Existing systems can’t handle the volume and speed requirements
- Real-time integration and access – Data silos prevent unified access to information
- Data governance and compliance – Ensuring security and regulatory compliance across all data uses
- Security and privacy – Protecting sensitive information while making it accessible to AI systems
The beauty of RAG is that it addresses these challenges without requiring companies to completely overhaul their existing data infrastructure. Instead, it creates a layer that can work with your current systems while gradually improving data organization and accessibility.
Real-world applications: How companies are using RAG
Let’s look at specific ways companies are already implementing RAG to transform their operations:
Customer support and service
Many companies are starting with RAG-powered chatbots for customer service representatives. Instead of agents spending minutes searching through multiple systems, they can ask natural language questions and receive instant, accurate responses with source attribution.
For example, a financial institution implemented RAG to help customer service agents. Previously, when customers asked about specific account features, agents had to navigate multiple legacy systems. Now, an agent can simply ask “What are the withdrawal limits for premium checking accounts?” and receive an immediate answer citing the exact policy documents, current as of the last system update.
Internal knowledge management
One of the most common early use cases involves creating “institutional memory” systems. Companies are using RAG to capture and make accessible the collective knowledge of their workforce — everything from engineering specifications to sales processes to compliance procedures.
A technology services company implemented RAG across their technical documentation, allowing engineers to ask complex questions like “What’s the standard procedure for debugging network connectivity issues in our cloud infrastructure?” The system can pull together information from troubleshooting guides, past incident reports, and architectural documentation to provide comprehensive, actionable answers.
Research and development
R&D teams are using RAG to accelerate innovation by making years of research findings, patent filings, and technical reports instantly searchable and analyzable. Instead of spending days or weeks researching prior work, teams can ask sophisticated questions about past projects and get comprehensive summaries with citations.
Compliance and risk management
Highly regulated industries are implementing RAG to help employees navigate complex compliance requirements. The system can instantly reference relevant regulations, internal policies, and historical decisions to provide guidance on specific situations.
A healthcare organization used RAG to help staff understand changing HIPAA requirements, allowing them to ask questions like “What are the new requirements for patient data sharing with third-party vendors?” and receive answers that cite current regulations, internal policies, and relevant legal guidance.
Key implementation considerations
Successfully implementing RAG requires careful planning and attention to several critical factors:
Start with a pilot use case
Gartner recommends selecting an initial pilot where business value can be clearly measured. The most successful implementations often begin with customer service, technical support, or internal knowledge management where the impact is immediately visible and quantifiable.
Choose a use case that has:
- Clear success metrics (response time, accuracy, user satisfaction)
- Well-defined data sources that are already relatively organized
- Users who are motivated to adopt new tools
- Manageable scope for initial implementation
Data classification and preparation
The next step involves classifying your data as structured, semi-structured, or unstructured, and determining the best approaches for handling each type. This classification helps you understand what pre-processing work is needed and what technologies will be most effective.
Structured data (databases, spreadsheets) often requires integration with your existing systems and may need schema mapping. Semi-structured data (XML, JSON files) typically needs parsing and normalization. Unstructured data (documents, emails, presentations) requires the most pre-processing, including text extraction, cleaning, and chunking for optimal retrieval.
Metadata is crucial
One of the most important but often overlooked aspects of RAG implementation is metadata management. Metadata provides the context that makes your RAG system truly intelligent. This includes:
- Source information – Where did this data come from?
- Date and version tracking – When was this information last updated?
- Access permissions – Who should be able to see this information?
- Content categorization – What department, project, or topic does this relate to?
- Quality indicators – How reliable or authoritative is this source?
Rich metadata allows your RAG system to provide not just relevant answers, but answers that respect your organization’s security requirements and provide proper context about the reliability and currency of information.
Technical architecture: Build vs. buy
One of the biggest decisions companies face is whether to build a custom RAG solution or use an enterprise platform. The choice significantly impacts timeline, cost, and ongoing maintenance requirements.
The DIY challenge
Building a RAG system from scratch typically involves 20+ APIs and 5–10 vendors. You’ll need to integrate:
- Document processing and text extraction tools
- Vector databases for storing embeddings
- Embedding models for converting text to vectors
- Search and ranking systems
- Language models for generation
- Monitoring and evaluation frameworks
- Security and access control systems
While this approach offers maximum flexibility, it also requires significant technical expertise and ongoing maintenance. Many companies find that the complexity quickly exceeds their initial estimates.
Enterprise RAG platforms
The alternative is using enterprise RAG platforms that provide end-to-end solutions. Leading platforms include:
- Elastic Enterprise Search – Combines traditional search with AI capabilities, built on widely-used vector database technology
- Pinecone – Serverless vector database with cascading retrieval systems that can improve search performance by up to 48%
- AWS Bedrock with Knowledge Bases – Fully managed service that handles vector conversions and retrievals automatically
- Vectara – End-to-end RAG platform designed specifically for enterprise deployments
Enterprise platforms typically reduce implementation time from months to weeks and provide production-ready infrastructure with enterprise-grade security, monitoring, and support.
Overcoming common implementation challenges
Even with the right platform, companies face several common challenges when implementing RAG:
Data synchronization
Keeping your RAG system updated as source data changes is critical but complex. You need systems that can detect when documents are updated, permissions change, or new information becomes available. Many companies start with scheduled batch updates but eventually move to real-time synchronization for critical data sources.
Access control and security
Your RAG system must respect existing access controls and not provide information to users who shouldn’t have access to the underlying data. This requires integrating with your identity management systems and implementing fine-grained permission controls.
Performance and scalability
As your RAG system grows, retrieval becomes a bottleneck. Enterprise implementations need robust search techniques like hybrid search (combining traditional keyword search with vector similarity) and reranking to maintain performance at scale.
Quality and hallucination management
While RAG significantly reduces AI hallucinations by grounding responses in real data, it doesn’t eliminate them entirely. Successful implementations include validation mechanisms, confidence scoring, and clear source attribution to help users evaluate the reliability of responses.
Measuring success and ROI
To justify ongoing investment in RAG systems, companies need clear success metrics. The most effective measurements typically include:
- Response time improvement – How much faster can employees find information?
- Accuracy rates – What percentage of responses are correct and helpful?
- User adoption – How many employees are actively using the system?
- Cost savings – Reduced time spent searching for information, fewer support tickets, faster onboarding
- Business impact – Improved customer satisfaction, faster decision-making, reduced compliance risks
According to Deloitte’s recent survey, 42% of organizations implementing generative AI (including RAG) are seeing significant gains in productivity, efficiency, and cost reduction. The key is setting baseline measurements before implementation and tracking improvements consistently.
The future of enterprise RAG
As we look toward 2026 and beyond, several trends are shaping the evolution of enterprise RAG:
Multimodal capabilities
RAG systems are expanding beyond text to include images, videos, and complex documents. This means your system will soon be able to analyze charts, diagrams, presentations, and video content alongside traditional text documents.
Agentic AI integration
The next generation of RAG will include AI agents that can not only retrieve and synthesize information but also take actions based on that information – scheduling meetings, updating records, or initiating processes based on corporate policies and procedures.
Improved personalization
RAG systems will become increasingly personalized, learning individual user preferences, roles, and access patterns to provide more relevant and contextual responses.
The competitive advantage of corporate knowledge
RAG represents more than just a technical solution – it’s a competitive strategy. In an era where information moves at digital speed, companies that can effectively leverage their institutional knowledge will have significant advantages in decision-making, customer service, and innovation.
The companies that invest in RAG architectures now are positioning themselves to capture value from their data assets while building the foundation for even more advanced AI capabilities in the future. As the technology continues to evolve, the gap between organizations that have successfully implemented RAG and those that haven’t will only widen.
Learn more
- Gartner’s Guide to RAG – Comprehensive enterprise perspective
- AWS RAG Overview – Technical implementation guide
- Enterprise RAG Predictions for 2025 – Industry trends and forecasts
- K2view RAG Practical Guide – Implementation best practices
- Enterprise RAG Trends 2024 – Current development patterns
- RAG Evolution 2024 – Technical advances and challenges
[…] we covered in our previous post on corporate RAG training, vector databases help AI chatbots give accurate answers by finding the right information to […]